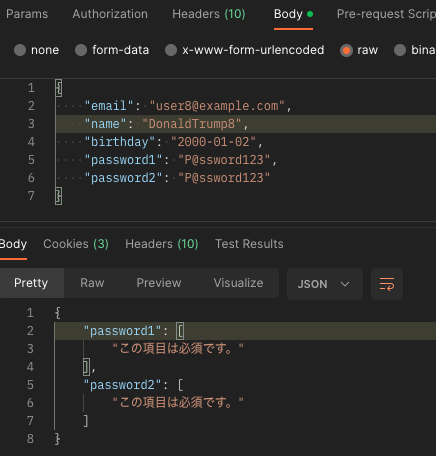
Django Rest Frameworkを使ってカスタムユーザーを使ってユーザー登録しようとした時、password1とpassword2を同じにして登録しているはずなのにパスワードが必須だと言われる。
{
"password1": [
"This field is required."
],
"password2": [
"This field is required."
]
}
(日本語版)
{
"password1": [
"この項目は必須です。"
],
"password2": [
"この項目は必須です。"
]
}
ネットでいくら探しても有力な解決法はなかったけれど、自分なりの解決法が見つかったのでブログに記すことにする。
qiita.com
一応Qiitaでも同様の現象が報告されているが解決策が力技すぎた。
当記事の原因とは違うなどどうしても解決できない場合は参考にしてみてほしい。
前提
認証には dj-rest-auth を使用。
今回作成したカスタムユーザーは以下の通り。
[accounts/models.py]
...
class User(AbstractBaseUser, PermissionsMixin, TimeStampedModel):
name = models.CharField(max_length=128, verbose_name=_('Name'), null=False, blank=True)
email = models.EmailField(unique=True, verbose_name=_('Email'))
icon = models.ImageField(verbose_name=_('Profile picture'), null=True, blank=True)
birthday = models.DateField(verbose_name=_('Birthday'), null=True, blank=True)
bio = models.TextField(verbose_name=_('Biography'), null=True, blank=True)
is_active = models.BooleanField(verbose_name=_('Is active'), default=True)
is_staff = models.BooleanField(verbose_name=_('Is staff'), default=False)
is_superuser = models.BooleanField(verbose_name=_('Is superuser'), default=False)
objects = CustomUserManager()
USERNAME_FIELD = 'email'
[accounts/serializers.py]
....
class UserRegisterSerializer(RegisterSerializer):
email = serializers.EmailField()
name = serializers.CharField(max_length=128)
birthday = serializers.DateField()
bio = serializers.CharField(required=False)
def get_cleaned_data(self):
return {
'username': self.validated_data.get('username', ''),
'password1': self.validated_data.get('password1', ''),
'email': self.validated_data.get('email', ''),
'name': self.validated_data.get('name', ''),
'birthday': self.validated_data.get('birthday', None),
'bio': self.validated_data.get('bio', None),
}
def custom_signup(self, request, user):
data = self.cleaned_data
user.name = data.get('name', '')
user.birthday = data.get('birthday', '')
user.bio = data.get('bio', '')
user.save()
modelsとserializersはこのように定義し、settingsでこのserializerをregisterに使うように設定した。
[project_name/settings.py]
...
REST_AUTH = {
"REGISTER_SERIALIZER": "accounts.serializers.UserRegisterSerializer",
}
...
ここまでの流れはだいたいこの記事の通りにした
Custom users using Django REST framework | Kraken Systems Ltd.
原因
原因は自分の場合、JSONの出力と入力をcamelCaseに対応させるため djangorestframework_camel_case を入れていたことが問題だった。
どうやら "password1" が "password_1" と解釈されるよう。
"password1"って書き方正式にはsnake_caseじゃないんですね。知らなかった…
この原因を突き止めるまで相当苦労した…
解決
暫定対応1
とりあえずcamelCaseを辞めるのを暫定対応とした。
つまり `settings.py` を書き換える。
REST_FRAMEWORK = {
'DEFAULT_RENDERER_CLASSES': (
'djangorestframework_camel_case.render.CamelCaseJSONRenderer',
'djangorestframework_camel_case.render.CamelCaseBrowsableAPIRenderer',
'rest_framework.renderers.JSONRenderer',
),
'DEFAULT_PARSER_CLASSES': (
'djangorestframework_camel_case.parser.CamelCaseFormParser',
'djangorestframework_camel_case.parser.CamelCaseMultiPartParser',
'djangorestframework_camel_case.parser.CamelCaseJSONParser',
'rest_framework.parsers.JSONParser',
),
こう書いていたのを
REST_FRAMEWORK = {
'DEFAULT_RENDERER_CLASSES': (
'rest_framework.renderers.JSONRenderer',
),
'DEFAULT_PARSER_CLASSES': (
'rest_framework.parsers.JSONParser',
),
こうする。
暫定対応2
とはいえフロントとの疎通の仕様上いまさらcamelCaseをsnake_caseに書き換えるのは無謀な話ということだった。
なのでどうにかならないかと思い悩んだ結果Serializerを書き換えることでなんとか対応できた。
具体的にはpassword1とされるところを徹底的にpassword_1に置き換えるという作業をした。
- 継承元の
serializers.Serializerでfieldの変数名を解釈している箇所"fields"
RegisterSerializerで"password1", "password2"という変数名を取って来て比較している箇所"validate"RegisterSerializerで"password1"というフィールドを取得する箇所"get_cleaned_data"
を書き換える必要があった。
from django.utils.functional import cached_property
class UserRegisterSerializer(RegisterSerializer):
email = serializers.EmailField()
name = serializers.CharField(max_length=128)
birthday = serializers.DateField()
bio = serializers.CharField(required=False)
@cached_property
def fields(self):
from rest_framework.utils.serializer_helpers import BindingDict
fields = BindingDict(self)
for key, value in self.get_fields().items():
if key == "password1":
key = "password_1"
if key == "password2":
key = "password_2"
fields[key] = value
return fields
def validate(self, data):
if data['password_1'] != data['password_2']:
raise serializers.ValidationError(_("The two password fields didn't match."))
return data
def get_cleaned_data(self):
return {
'username': self.validated_data.get('username', ''),
'password1': self.validated_data.get('password_1', ''),
'email': self.validated_data.get('email', ''),
'name': self.validated_data.get('name', ''),
'birthday': self.validated_data.get('birthday', None),
'bio': self.validated_data.get('bio', None),
}
def custom_signup(self, request, user):
data = self.cleaned_data
user.name = data.get('name', '')
user.birthday = data.get('birthday', '')
user.bio = data.get('bio', '')
user.save()
継承元のserializers.Serializer の関数をオーバーライドするという魔改造なのでDjangoの仕様が変わるとそれに対応できなくなるという怖さがある。